생성형 AI의 역습과 포스트 챗봇 시대 인공지능이 재편하는 디지털 생태계
단순한 대화를 넘어 사용자의 의도를 수행하는 '액션형 AI'가 등장하며, 기존 웹 검색과 앱 생태계를 대체하는 거대한 패러다임 전환이 시작되었다.

오픈AI·구글·메타의 삼각 편대 속 '에이전트' 중심의 인터페이스 혁명
저작권 분쟁과 훈련 데이터 고갈 문제 직면하며 '합성 데이터' 대안 부상
하드웨어와 소프트웨어 경계 허무는 온디바이스 AI 기기의 습격
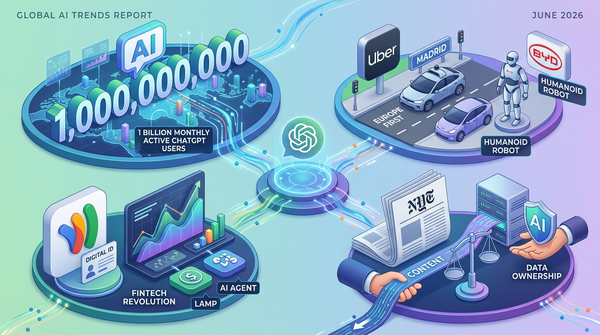
인공지능(AI) 기술이 단순히 질문에 답하는 수준을 넘어, 사용자의 디지털 삶 전체를 대행하는 ‘에이전트(Agent)’ 시대로 급격히 진화하고 있다. 글로벌 테크 미디어 더버지(The Verge)에 따르면, 최근 AI 산업의 화두는 모델의 크기 경쟁에서 ‘실행력’과 ‘접점’의 경쟁으로 옮겨갔다. 오픈AI의 GPT-5(가칭)와 구글의 제미나이 2.0이 예고된 가운데, 이제 업계의 시선은 누가 더 인간의 복잡한 업무 프로세스를 완벽히 대행하느냐에 쏠려 있다.
검색의 종말과 에이전트 인터페이스의 부상
지난 수십 년간 인터넷의 관문 역할을 했던 ‘검색 창’이 사라지고 있다. 구글의 ‘AI 개요(AI Overviews)’와 퍼플렉시티(Perplexity) 같은 답변 엔진이 주류로 부상하면서, 사용자는 더 이상 수많은 링크를 클릭해 정보를 조합하지 않는다. 이러한 변화는 웹 생태계의 근간인 광고 수익 모델에 치명적인 위협이 되고 있으며, 언론사와 콘텐츠 제작자들은 AI 기업들을 상대로 저작권 방어와 정당한 대가 지불을 요구하는 고차원적인 법적 투쟁을 이어가고 있다.
특히 마이크로소프트와 애플이 운영체제(OS) 깊숙이 AI를 이식하면서, 이제 AI는 브라우저 안의 기능이 아닌 시스템 그 자체가 되었다. 사용자의 화면을 실시간으로 인식하고 맥락을 이해하는 ‘리콜(Recall)’ 기능이나 애플의 ‘인텔리전스’는 AI가 단순한 도구를 넘어 개인의 비서로서 작동하는 ‘에이전틱 워크플로우(Agentic Workflow)’의 시작을 알리고 있다.
데이터 고갈 위기와 합성 데이터의 역설
AI 모델 학습에 필요한 고품질의 인간 데이터가 바닥을 드러내면서 기술적 임계점에 도달했다는 분석도 나온다. 레딧(Reddit), 위키피디아, 그리고 주요 언론사들이 무단 크롤링을 차단하자, 빅테크 기업들은 AI가 생성한 데이터를 다시 AI가 학습하는 ‘합성 데이터(Synthetic Data)’ 기술에 사활을 걸고 있다. 하지만 이는 모델이 점차 멍청해지는 ‘모델 붕괴(Model Collapse)’ 현상을 초래할 수 있다는 경고를 동반하며, 양질의 데이터 확보가 곧 기업의 생존권과 직결되는 양상으로 치닫고 있다.
이와 동시에 엔비디아의 독주 체제에 대항하는 ‘반(反) 엔비디아 전선’도 구체화되고 있다. 구글, 아마존, 메타 등은 천문학적인 비용이 드는 GPU 의존도를 낮추기 위해 자체 AI 가속기(LPU) 개발에 박차를 가하고 있다. 이는 하드웨어 인프라 장악력이 곧 소프트웨어 서비스의 단가 경쟁력으로 이어지는 AI 경제학의 논리가 작용한 결과다.
온디바이스 AI 하드웨어의 새로운 도전
소프트웨어의 진화는 하드웨어의 폼팩터 변화를 강제하고 있다. 스마트폰을 대체하려는 시도로 평가받는 AI 핀(Ai Pin)이나 래빗(Rabbit) R1과 같은 전용 기기들이 시장의 시험대에 올랐다. 비록 초기 모델들은 성능 면에서 혹평을 받기도 했으나, 시각 지능을 갖춘 스마트 글래스와 웨어러블 기기들이 쏟아지며 ‘스크린 없는 컴퓨팅’에 대한 실험은 멈추지 않고 있다.
결국 2026년 하반기 AI 시장은 기술적 화려함을 넘어 ‘실용성’과 ‘윤리적 책임’이라는 두 가지 시험대를 마주하고 있다. 딥페이크를 이용한 선거 개입과 가짜 뉴스 확산 등 사회적 리스크가 커지는 가운데, 유럽의 AI 법(EU AI Act)을 필두로 한 글로벌 규제의 파고가 혁신의 속도를 조절하는 변수로 작용할 전망이다. 인공지능은 이제 단순한 기술 트렌드를 넘어, 인류가 정보를 소비하고 생산하는 방식 자체를 근본적으로 재정의하고 있다.